News
-
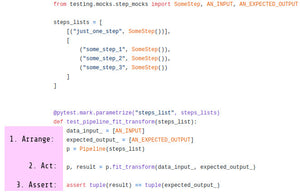
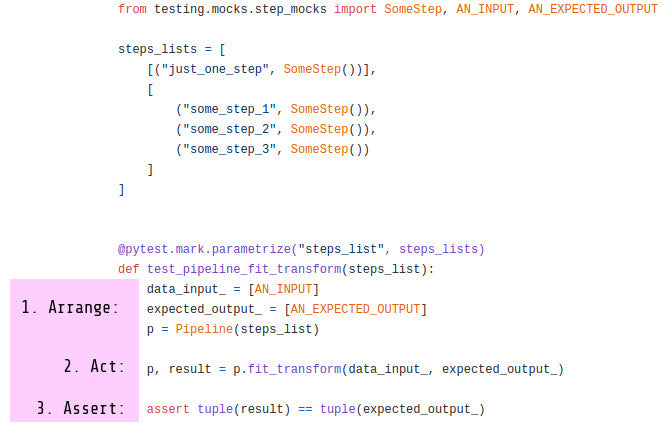
How to unit test machine learning code?
by Guillaume ChevalierWhy are unit tests important? Why is testing important? How to do it for machine learning code? Those are questions I will answer. I suggest that ... -


Our top learning resources for AI programmers
by Guillaume ChevalierYou are an Artificial Intelligence (AI) programmer and you'd like to learn how to program well as we do at Neuraxio? Lucky you, we've launched a s... -


Clean Machine Learning Training
by Guillaume ChevalierApplying clean code and SOLID principles to your ML projects is crucial, and is so often overlooked. Successful artificial intelligence projects require good programmers to work in pair with the mathematicians.
Ugly research code simply won’t do it. You need to do Clean Machine Learning at the moment you begin your project.
Despite all the hype being about the deep learning algorithms, we decided at Neuraxio to do a training about Clean Machine Learning, because it is was we feel the industry really needs.
Clean code is excessively hard to achieve in a codebase that is already dirty, action truly must be taken at the beginning of the project. It must not be postponed.
-


What is Automated Machine Learning (AutoML)? - A Metaphor
by Guillaume ChevalierDaily, what does a data scientist do? And how can Automated Machine Learning avoid you to babysit your AI, practically?
Here is a metaphor: your data scientist is a mom. A babysitter.
The data scientist creates a nice artificial neural network and trains it on data. Then he’s going to supervise the learning. The data scientist will make sure that the learning converges in the right way so that the artificial neural network can give good predictions and then flourish.
Seriously, that’s all well and good, but it costs time, and it costs money.
Is there anything we can do to automate the process of being a mom - actually being a data scientist? Actually, we can use Automated Machine Learning.
-


What's Wrong with Scikit-Learn Pipelines?
by Guillaume ChevalierScikit-Learn’s “pipe and filter” design pattern is simply beautiful. But how to use it for Deep Learning, AutoML, and complex production-level pipelines?
Scikit-Learn had its first release in 2007, which was a pre deep learning era. It’s one of the most known and adopted machine learning library, and is still growing. On top of all, it uses the Pipe and Filter design pattern as a software architectural style - it’s what makes Scikit-Learn so fabulous, added to the fact it provides algorithms ready for use. However, it has massive issues when it comes to do the following, which we should be able to do in 2020 already:
- Automatic Machine Learning (AutoML),
- Deep Learning Pipelines,
- More complex Machine Learning pipelines.
Let’s first clarify what’s missing exactly, and then let’s see how we solved each of those problems with building new design patterns based on the ones Scikit-Learn already uses.
TL;DR: How could things work to allow us to do what’s in the above list with the Pipe and Filter design pattern / architectural style that is particular of Scikit-Learn? The API must be redesigned to include broader functionalities, such as allowing the definition of hyperparameter spaces, and allowing a more comprehensive object lifecycle & data flow functionalities in the steps of a pipeline. We coded a solution: that is Neuraxle.
Don’t get me wrong, I used to love Scikit-Learn, and I still love to use it. It is a nice status quo: it offers useful features such as the ability to define pipelines with a panoply of premade machine learning algorithms. However, there are serious problems that they just couldn’t see in 2007, when deep learning wasn’t a thing.
-


A Rant on Kaggle Competition Code (and Most Research Code)
by Guillaume ChevalierMachine Learning competition & research code sucks. What to do about it?
As a frequent reader of source code coming from Kaggle competitions, I’ve come to realize that it wasn’t full of rainbows, unicorns, and leprechauns. It’s rather like a Frankenstein. A Frankenstein is a work made of glued parts of other works and badly integrated. Machine Learning competition code in general, as well as machine learning research code, suffer from deep architectural issues. What to do about it? Using neat design patterns can change a lot of things for the better.
EDIT - NOTE TO THE READER: this article is written with having in mind a context where said competition code is to be reused to put it in production. The arguments in this article are oriented towards this end-goal. We are conscious that it’s natural and time-efficient for kagglers and researchers to write dirty code as their code is for a one-off thing. Reusing such code to build a production-ready pipeline is another thing, and the road to get there is bumpy.
TL;DR: don’t directly reuse competition code. Instead, create a new, clean project on the side, and refactor the old code into it.
-


How to Code Neat Machine Learning Pipelines
by Guillaume ChevalierCoding Machine Learning Pipelines - the right way.
Have you ever coded an ML pipeline which was taking a lot of time to run? Or worse: have you ever got to the point where you needed to save on disk intermediate parts of the pipeline to be able to focus on one step at a time by using checkpoints? Or even worse: have you ever tried to refactor such poorly-written machine learning code to put it to production, and it took you months? Well, we’ve all been there if working on machine learning pipelines for long enough. So how should we build a good pipeline that will give us flexibility and the ability to easily refactor the code to put it in production later?
First, we’ll define machine learning pipelines and explore the idea of using checkpoints between the pipeline’s steps. Then, we’ll see how we can implement such checkpoints in a way that you won’t shoot yourself in the foot when it comes to put your pipeline to production. We’ll also discuss of data streaming, and then of Oriented Object Programming (OOP) encapsulation tradeoffs that can happen in pipelines when specifying hyperparameters.
-


Hello World!















