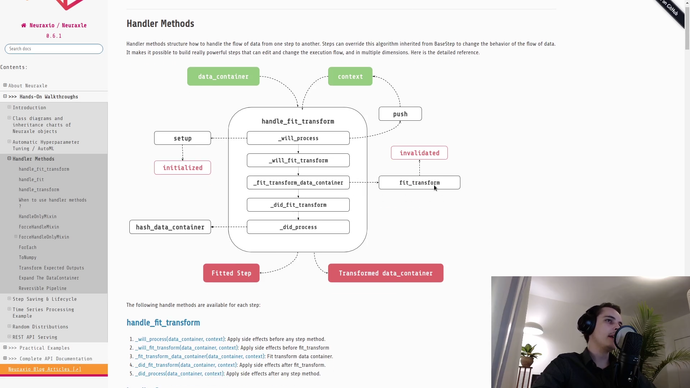
Scikit-Learn’s “pipe and filter” design pattern is simply beautiful. But how to use it for Deep Learning, AutoML, and complex production-level pipelines?
Scikit-Learn had its first release in 2007, which was a pre deep learning era. It’s one of the most known and adopted machine learning library, and is still growing. On top of all, it uses the Pipe and Filter design pattern as a software architectural style - it’s what makes Scikit-Learn so fabulous, added to the fact it provides algorithms ready for use. However, it has massive issues when it comes to do the following, which we should be able to do in 2020 already:
- Automatic Machine Learning (AutoML),
- Deep Learning Pipelines,
- More complex Machine Learning pipelines.
Let’s first clarify what’s missing exactly, and then let’s see how we solved each of those problems with building new design patterns based on the ones Scikit-Learn already uses.
TL;DR: How could things work to allow us to do what’s in the above list with the Pipe and Filter design pattern / architectural style that is particular of Scikit-Learn? The API must be redesigned to include broader functionalities, such as allowing the definition of hyperparameter spaces, and allowing a more comprehensive object lifecycle & data flow functionalities in the steps of a pipeline. We coded a solution: that is Neuraxle.
Don’t get me wrong, I used to love Scikit-Learn, and I still love to use it. It is a nice status quo: it offers useful features such as the ability to define pipelines with a panoply of premade machine learning algorithms. However, there are serious problems that they just couldn’t see in 2007, when deep learning wasn’t a thing.