A Rant on Kaggle Competition Code (and Most Research Code)
Machine Learning competition & research code sucks. What to do about it?
As a frequent reader of source code coming from Kaggle competitions, I’ve come to realize that it wasn’t full of rainbows, unicorns, and leprechauns. It’s rather like a Frankenstein. A Frankenstein is a work made of glued parts of other works and badly integrated. Machine Learning competition code in general, as well as machine learning research code, suffer from deep architectural issues. What to do about it? Using neat design patterns can change a lot of things for the better.
EDIT - NOTE TO THE READER: this article is written with having in mind a context where said competition code is to be reused to put it in production. The arguments in this article are oriented towards this end-goal. We are conscious that it’s natural and time-efficient for kagglers and researchers to write dirty code as their code is for a one-off thing. Reusing such code to build a production-ready pipeline is another thing, and the road to get there is bumpy.
TL;DR: don’t directly reuse competition code. Instead, create a new, clean project on the side, and refactor the old code into it.
Bad Design Patterns.
It’s so common to see code coming from Kaggle competitions that lacks the proper object oriented abstractions. Moreover, they also lack the abstractions for allowing to later deploying the pipeline to production - and with reason, kagglers have no incentives to prepare for deploying code to production, as they only need to win the competition.
The situation is roughly the same in academia where researchers too often just try to get results, beating a benchmark, to publish a paper and ditch the code after. Worse: often times, those researchers use overused datasets, and it requires for them to use all sorts of very specific post-processing tricks that won’t generalize to any other dataset, nor a production version of the algorithm for real-world usage.
Unfortunately, companies often rely on beating public benchmarks to only later discover that just having a working algorithm first may be of better value, without maniacally overtuning the algorithm on one very specific dataset. To make things worse, many machine learning coders and data scientists didn’t learn to code properly in the first place, so those prototypes are often full of technical debt.
Here are a few examples of bad patterns we’ve seen:
- Coding a pipeline using bunch of manual small “main” files to be executed one by one in a certain order, in parallel or one after the other. Yes, we saw that many times.
- Forcing to use disk persistence between the aforementioned small main files, which strongly couple the code to the storage and makes it impossible to run the code without saving to disk. Yes, many times.
- Making the disk persistence mechanism different for each of those small “main” files. For example, using a mix of JSON, then CSV, then Pickles and sometimes HDF5 and otherwise raw numpy array dumps. Or even worse : mixing up many databases and bigger frameworks instead of keeping it simple and writing to disks. Yikes! Keep it simple!
- Provide no instructions whatsoever on how to run things in the good order. Bullcrap is left as an exercise for the reader.
- Have no unit tests, or unit tests that yes-do-test the algorithm, but that also requires writing to disks or using what was already written to disks. Ugh. And by the time you execute that untested code again, you end up with an updated dependency for which no installation version was provided and nothing work as it did anymore.
Pointing to Some Examples
Those bad patterns doesn’t only apply to code written in programming competition environments (such as this code of mine written in a rush - yes, I can do it too when unavoidably pressured). Here are some examples of code with checkpoints using the disks:
- Most winning Kaggle competition code. We dove many times in such code, and it never occurred to us to see the proper abstractions.
- BERT. Bear with me - just try to refactor “run_squad.py” for a second, and you’ll realize that every level of abstraction are coupled together. To name a few, the console argument parsing logic is mixed up at the same level of the model definition logic, full of global flag variables. Not only that, the model definition logic is mixed in all of this, along with the data loading and saving logic that uses the cloud, in one huge file of more than 1k lines of code in a small project.
- FastText. The Python API is made for loading text files from disks, training on that, and dumping on disk the result. Couldn’t dumping on disk and using text files as training input be optional?
Using Competition Code?
Companies can sometimes draw inspiration from code on Kaggle, I’d advise them to code their own pipelines to be production-proof, as taking such competition as-is is risky. There is a saying that competition code is the worst code for companies to use, and even that the people winning competitions are the worst once to hire - because they write poor code.
I wouldn’t go that far in that saying (as I myself most of the time earn podiums in coding competitions) - it’s rather that competition code is written without thinking of the future as the goal is to win. Ironically, it’s at that moment that reading Clean Code and Clean Coder gets important. Using good pipeline abstractions helps machine learning projects surviving.
Solving the Problems.
So you still want to use competition and research code for you production pipeline. You’ll probably need to start anew and refactor the old code into the proper new abstractions. Here are the things you want when building a machine learning pipeline which goal is to be sent to production:
- You ideally want a pipeline than can process your data by calling just one function and not lots of small executable files. You might have some caching enabled if things are too slow to run, but you keep caching as minimal as possible, and your caching might not be checkpoints exactly.
- Having the possibility to not use any data checkpoints between pipeline steps simply. You want to be able to deactivate all your pipeline’s checkpoints easily. Checkpoints are good for training the model, debugging it and actively coding the pipeline, but in production it’s just heavy and it must be easily disableable.
- The ability to scale your ML pipeline on a cluster of machines.
- Finally, you want the whole thing to be robust to errors and to do good predictions. Automatic Machine Learning can help here.
And if your goal is instead to continue to do competitions, please at least note that I (personally) started winning more competitions after reading the book Clean Code. So the solutions above should as well apply in competitions, you’ll have more mental clarity, and as a result, more speed too, even if designing and thinking about your code beforehand seems like taking a lot of precious time. You’ll start saving even in the short run, quickly.
Now that we’ve built a machine learning framework that ease the process of writing clean pipelines, we have a hard time picturing how we’d get back to our previous habits anytime. Clean is our new habit, and it now doesn’t cost much more time to start new projects with the good abstractions from the start, as we’ve already thought through them.
Another upside, if you’re a researcher, is that if your code is developer-friendly and has a good API, it has more chances of being reused, thus you’ll be more likely to be cited. It’s always sad to discover that some research results can’t be reproduced even when using the same code that generated those results.
In all cases, using good patterns and good practices will almost always save time even in the short or medium term. For instance, using the pipe and filter design pattern with Neuraxle is the simplest and cleanest thing to do.
Conclusion
It’s hard to write good code when pressured by the deadline of a competition. We created Neuraxle to easily allow for the good abstractions to be easily used when in a rush. As a result, it’s a good thing that competition code be refactored into Neuraxle code, and it’s a good idea to write all your future code using a framework like Neuraxle.
The future is now. If you’d like to support Neuraxle, we’ll be glad that you get in touch with us. You can also register to our updates and follow us. Cheers!
Related Posts
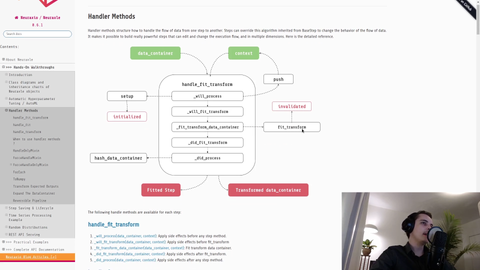
Structuring Machine Learning Code: Design Patterns & Clean Code

How Machine Learning Will Improve the Workforce
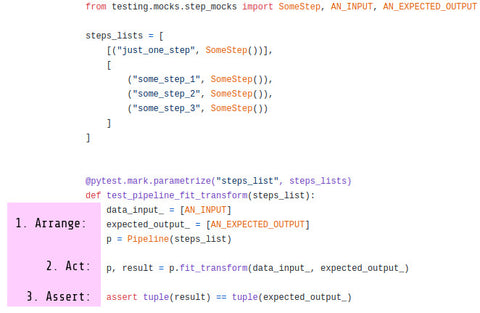
How to unit test machine learning code?
Back to News