What is Automated Machine Learning (AutoML)? - A Metaphor
Daily, what does a data scientist do? And how can Automated Machine Learning avoid you to babysit your AI, practically?
Here is a metaphor: your data scientist is a mom. A babysitter.
The data scientist creates a nice artificial neural network and trains it on data. Then he’s going to supervise the learning. The data scientist will make sure that the learning converges in the right way so that the artificial neural network (or model) can give good predictions and then flourish.
Seriously, that’s all well and good, but it costs time, and it costs money.
Is there anything we can do to automate the process of being a mom - actually being a data scientist? Actually, we can use Automated Machine Learning.
Automated Machine Learning allows us to automate the process of being a mom.
Doing Automated Machine Learning (AutoML)
Firstly, when we define a model, an artificial neural network for example, we have to define the hyperparameters: The number of neurons, the number of layers of neurons on top of each other.
So we’re going to define things like the learning rate, and then the way the data is formatted to send it to the Artificial Neural Network (ANN).
Those are hyperparameters and they are all very well, but above that, to do Automated Machine Learning, we can actually define a space of hyperparameters. E.g.: the number of neurons varies between this and that.
The data can be formatted to send a certain amount of data of a certain length or a certain shape. You can disable or enable certain pre-processing steps in the data.
We can have a space in which, if we pick a point in that space, we find a special case like finally sampling a gene - a hyperparameter - a hyperparameter sample for our artificial neural network.
In other words, every point (sample) in the space is a different setting (or gene) to try.
With Automated Machine Learning, we can finally iterate in this space to pick up new points, try them out, in a somewhat random way, but still intelligent, so that after having made several attempts, converge towards a result.
The True Added Benefits of Automated Machine Learning
- It avoids the data scientist to constantly have to supervise the model and to wait for the learning to finish.
- It will also allow the model to finally run during the night.
- The whole process will be repeatable later whenever the dataset, B2C or B2B client, or project changes!
There’s no need for the data scientist to be around all the time. AutoML can run for weeks, even months, for larger models if you want, and so on. With all this, eventually, then we can get the best results.
Moreover, it makes easier reusing the code of your last project into your next one. Which provides even more speed in the long run.
Hyperparameter Tuning is an Important Aspect of Every Machine Learning Project
We can also analyze the effect of hyperparameters on neural network’s performance. That’s a problem in data science: the neural networks or the model that’s going to perform best on a set of data, isn’t the model with the most neurons, nor the model with the most everything.
In fact, it’s not the one with the least neither. It has to be somewhere in between. You have to find what’s best - there’s a trade-off between bias and then variance.
- A biased model is going to take some stupid rules of thumb eventually. Maybe it lacks complexity, it lacks neurons, and something’s going on, that’s not good enough in all of this.
- Then a model, on the contrary, that has a lot of variance, has so much learning abilities that, yes, it will pass every exercise during training, but when it comes to the test, it won’t be able to generalize the substance of it correctly. He’s going to end up rote in the end. He’s going to memorize the questions and answers and then, because he was too smart, there was like too much memory or something like that, and then by the time he gets to the test, he’s not going to be able to generalize what he should have. He’s going to be lazy, and then he’s going to get bad results.
In the end, that’s one of the things we’re going to automate with Automated Machine Learning: finding the best model with a good bias/variance tradeoff.
That’s why we need a data scientist or Automated Machine Learning to supervise the artificial neural network, and then try and retry different hyperparameters, as there are no free lunches (NFL theorem).
Conclusion
There are different algorithms that allow you to choose the next point - not by chance - you can analyze what you’ve tried, and what the results were, and then pick the next point in space, and try it all out in an intelligent way.
Machine Learning software has more value if it has the ability to be automatically adapted to new data or a new dataset later on when things will change. The ability to adapt quickly to new data and changes in requirements is important. Those two factors that are often ignored are important in explaining why 87% of data science projects never make it into production.
In our projects, we use the free tool Neuraxle to optimize our Machine Learning algorithms’ hyperparameters. The trick is to define an hyperparameter space for our models and even for our data preprocessing functions using the good software abstraction for ML.
Related Posts
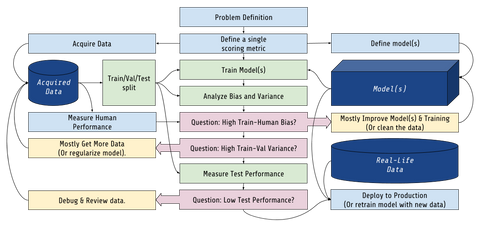
The Business Process of Machine Learning, with AutoML
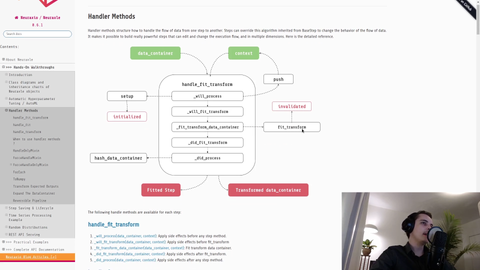
Structuring Machine Learning Code: Design Patterns & Clean Code

How Machine Learning Will Improve the Workforce
Back to News